
Page Under Development
This page is still “under development”. Please contact the webmaster@advanced-steam.org if you would like to help by contributing text to this or any other page.
Definitions of thermodynamic concepts such as Entropy and Enthalpy are provided on separate pages of this website. Numerous useful (and often diverse) definitions of these and other terms can be found on the Internet.
A particularly useful (and brief) discussion can be found here (from http://www.mathpages.com/home/kmath184/kmath184.htm).
Adiabatic Process
An adiabatic process is one in which there is no transfer of heat between the system and its surroundings. Thus in thermodynamic nomenclature, Q (heat transfer to or from a system) = 0
Adiabatic expansion can occur in a well-insulated system. Neglecting kinetic energy, electrical energy, etc, the drop in enthalpy of the system is effectively converted to work (dH = Q + W, where Q = 0). An adiabatic expanion is thus considered to be most expanion that can occur.
Adiabatic Efficiency is the ratio of the actual work output of the engine to the work output that would be achieved if the process between the inlet state and the exit state was isentropic (see below).
Isentropic (or Isoentropic) Process and Isentropic Efficiency
An isentropic process is an ideal or “perfect” process in which entropy remains constant. For a reversible isentropic process, there is no transfer of heat energy and therefore the process is also adiabatic.
If a process is both adiabatic and reversible, then it is considered to be isoentropic.
Isentropic expansion of steam is represented as a vertical line on a Mollier h-s diagram. However expansion of steam is never perfect and some increase in entropy cannot be avoided. Real expansion is represented by a sloping (non-vertical) line, the angle of slope being indicative of the isentropic efficiency of the expansion.
In the case of a steam locomotive, the isentropic efficiency of the expansion of steam in the cylinder is found by dividing the specific work done in the cylinder by the isentropic heat drop between admission and exhaust. It therefore defines the efficiency of the engine unit (i.e. cylinders, valves etc) in terms of the amount of work it delivers from each stroke compared to the isentropic heat drop of the steam between admission and release.
Isentropic efficiency is therefore a measure of the efficiency of the engine unit. As with a locomotive’s thermal efficiency, its isentropioc efficiency varies with speed, cut-off, steamchest pressure etc.
An example appears in the 5AT FDCs, where lines 68 to 84 of FDC 1.3 are used to calculate the isentropic efficiency of the 5AT at maximum drawbar power.
An example of isentropic efficiency being applied in a calculation can be found here.
Isenthalpic (or Isoenthalpic) Process
An isenthalpic process is one that proceeds without any change in enthalpy (H) or specific enthalpy (h). There will usually be significant changes in pressure and temperature during the process.
In a steady-state, steady-flow process, significant changes in pressure and temperature can occur to a fluid. However the process will be isenthalpic if
- there is no transfer of heat to or from the surroundings (i.e. it is adiabatic),
- there is no work done on or by the surroundings, and
- there is no change in the kinetic energy of the fluid.
The throttling process is an example of an isenthalpic process – for instance the lifting of a safety valve on a steam boiler. The specific enthalpy of the steam inside the boiler is the same as the specific enthalpy of the steam as it escapes from the valve. Thus with a knowledge of the specific enthalpy of the steam and the pressure outside the pressure vessel, it is possible to determine the temperature and speed of the escaping fluid.
In an isenthalpic process: h1 = h2 and therefore dh = 0.
The above definition comes from Wikipedia and also World Lingo which offers an almost identical definition. However neither is entirely satisfactory since steam escaping through a safety valve will experience rapid cooling in its surroundings. The diagram below (from Chemical and Process Technology) gives a clearer picture even if the accompanying explanation is less so.
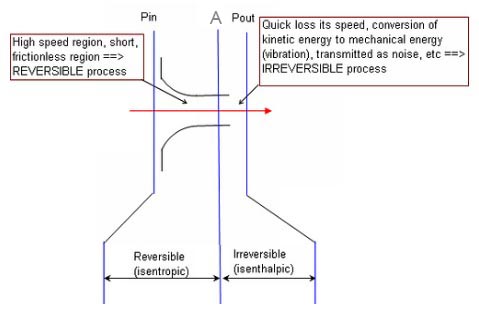 An interpretation of the accompanying explanation is offered as follows:
An interpretation of the accompanying explanation is offered as follows:
The flow through a pressure relief valve is extremely fast. Choked flow can occurs as far as position A inside the nozzle. The flow from the inlet to “A” will be a REVERSIBLE process and thus an ISENTROPIC process. Beyond “A” to the outlet of the valve, the steam expands (it may even undergo a change in state if it is liquid prior to “A” resulting in a transformation energy loss) followed by a rapid loss of speed and conversion of kinetic energy to mechanical energy in the form of noise. However the enthalpy remains constant (ISENTHALPIC). This process is IRREVERSIBLE (i.e. entropy increases).
Heat Capacity Ratio, Isentropic Expansion Factor, or Expansion Coefficient
[Ref Wikipedia] The Heat Capacity Ratio is sometimes also known as the “isentropic expansion factor“. In the 5AT FDCs, the expansion factor is termed the “expansion coefficient” and denominated by the letter ‘n’. In other texts it may be denoted by γ, κ or the letter k.
The value of n is derived from the equation: n = Cp / Cv where, C is the heat capacity of a gas, suffix P and V refer to constant pressure and constant volume conditions respectively.
The heat capacity ratio (expansion coefficient) ‘n’ can be visualized from the following experiment:
A closed cylinder with a locked piston contains air. The pressure inside is equal to the outside air pressure. This cylinder is heated to a certain target temperature. Since the piston cannot move, the volume is constant, while temperature and pressure rise. When the target temperature is reached, the heating is stopped. The piston is now freed and moves outwards, expanding without exchange of heat (adiabatic expansion). Doing this work cools the air inside the cylinder to below the target temperature. To return to the target temperature (still with a free piston), the air must be heated. This extra heat amounts to about 40% more than the previous amount added.
In this example, the amount of heat added with a locked piston is proportional to CV, whereas the total amount of heat added is proportional to CP. Therefore, the heat capacity ratio in this example is 1.4.
From Steam Tables the following outputs can be found (based on a pressure of 20 bar)
| Pressure = 20 bar | 200oC | 300oC | 400oC | 450oC | |
| Cv | kJ/(kg.oC) | 2.06657 | 1.696 | 1.66439 | 1.67895 |
| Cp | kJ/(kg.oC) | 2.98955 | 2.32035 | 2.2013 | 2.19664 |
| n | – | 1.35 | 1.37 | 1.32 | 1.31 |
The coefficient is usually given the value 1.3 in SGS locomotive performance calculations.
Reversible Process
A reversible process is a process that, after it has taken place, can be reversed and causes no change in either the system in which the process takes place, and causes no change in its surroundings. In thermodynamic terms, a process “taking place” would refer to its transition from its initial state to its final state. Or put another way, a reversible process changes the state of a system in such a way that the net change in the combined entropy of the system and its surroundings is zero.
Since all processes involve some increase in entropy (however small), the concept of reversibility is an ideal one that can never be achieved in practice. However the concept of reversible processes is a useful one. For instance, it is used to define the maximum possible efficiency (the isentropic efficiency) of a heat engine in that a reversible process is one where no heat is lost from the system as “waste”, and the machine is thus as efficient as it can possibly be (see Carnot cycle).
A reversible process is thus of necessity an isentropic process.
Specific Volume: Specific volume of a gas is the inverse of its density. It is therefore a measure of volume per unit of mass. In steam tables, its units are usually given as m3/kg (or lb/ft3 in the old units).